Embedding Model Evaluation
There is a wide range of embedding models out there so I need to test which one is best for our use case. I then also need to find out the optimal threshold. As I just explained I’m going to be finding duplicates using cosine similarities. And as I’ve outlined these similarities are values from -1 to 1. This means I’m going to have to decide from which value on I classify a similarity match as a duplicate.
To determine these two factors, I tested three models:
- OpenAI’s text-embedding-ada-002: A widely used model known for its strong semantic understanding.
- OpenAI’s text-embedding-3-small: A more recent and cost-effective model offering promising performance.
- SentenceTransformer (all-MiniLM-L6-v2): A free, locally-run embedding model often used as a base line for local embedding model.
I wrote a script to conduct automated tests on an expanded dataset consisting of 40 chosen pairs of thesis points, each pair manually labeled as either duplicate (1) or non-duplicate (0). Evaluation metrics included:
- Accuracy: Percentage of correct predictions overall.
- Precision: Proportion of true duplicate points among all points identified as duplicates.
- Recall: Proportion of true duplicates correctly identified out of all actual duplicate pairs.
- F1 Score: Harmonic mean of precision and recall, offering a balanced evaluation metric.
Below are the detailed results of these tests at their optimal thresholds:
| Model | Avg. Similarity (Duplicates) | Avg. Similarity (Non-Duplicates) | Optimal Threshold | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|---|---|
| text-embedding-ada-002 | 0.926 | 0.795 | 0.85 | 0.950 | 1.000 | 0.917 | 0.957 |
| text-embedding-3-small | 0.737 | 0.329 | 0.60 | 0.950 | 1.000 | 0.917 | 0.957 |
| SentenceTransformer MiniLM | 0.661 | 0.216 | 0.40 | 1.000 | 1.000 | 1.000 | 1.000 |
Model-by-Model Analysis
1. OpenAI text-embedding-ada-002
-
Average Similarity:
-
Duplicate pairs: 0.934
-
Non-duplicate pairs: 0.794
-
-
Observations:
-
The high similarity scores for both duplicate and non-duplicate pairs indicate that ada-002 produces a very compressed similarity range.
-
A very high threshold (around 0.85–0.90) is required to start differentiating duplicates, as shown by the jump in accuracy (up to 0.975–0.950) and F1 scores (0.978–0.955) at those thresholds.
-
However, this narrow margin makes the model highly sensitive to small changes in input; a slight variation might easily push a non-duplicate over the threshold.
-
-
Implication:
- While ada-002 can perform well when the threshold is set very high, its limited separation between duplicates and non-duplicates makes it less robust for the application.
2. OpenAI text-embedding-3-small
-
Average Similarity:
-
Duplicate pairs: 0.757
-
Non-duplicate pairs: 0.306
-
-
Observations:
-
This model provides a robust gap of about 0.451 between duplicates and non-duplicates.
-
Evaluation metrics steadily improve with increasing thresholds, reaching high F1 scores (up to 0.978 at a threshold of 0.60) and maintaining good precision and recall over a relatively wide threshold range (from about 0.45 to 0.60).
-
-
Implication:
- The 3-small model shows reliable and stable performance across a moderate range of thresholds, which is beneficial in production environments where inputs may vary. Its clear separation suggests it can serve as a robust pre-filter.
3. SentenceTransformer (all-MiniLM-L6-v2) – MiniLM
-
Average Similarity:
-
Duplicate pairs: 0.698
-
Non-duplicate pairs: 0.195
-
-
Observations:
-
MiniLM yields a strong gap of approximately 0.503 between duplicate and non-duplicate pairs.
-
It achieves perfect classification (accuracy, precision, recall, and F1 all equal to 1.000) at a threshold of 0.40.
-
However, the performance is highly sensitive-if the threshold shifts even slightly above 0.40, the F1 score drops (e.g., 0.978 at 0.45, then lower at higher thresholds).
-
-
Implication:
- Despite its sensitivity to threshold variations, MiniLM’s outstanding performance in controlled testing indicates its high potential for accurate duplicate detection. I later tested this model in comparison with FinLang on some real world data and MiniLM performed a lot better (although it is crucial to note i tested on a very small dataset). Overall I’ll choose MiniLM for now but will continue monitoring performance after deployment to make sure it outperforms FinLang.
4. FinLang (Investopedia-trained model)
-
Average Similarity:
-
Duplicate pairs: 0.783
-
Non-duplicate pairs: 0.292
-
-
Observations:
-
FinLang produces a gap of about 0.491 between duplicate and non-duplicate pairs.
-
Its evaluation metrics peak at thresholds between 0.40 and 0.45, with accuracy around 0.95, near-perfect precision (up to 1.000), recall close to 0.957, and F1 scores around 0.958.
-
Performance remains stable over this moderate threshold range.
-
-
Implication:
- FinLang is specifically tuned on financial data, which is a significant advantage for this use case. It shows excellent performance at a moderate threshold, making it robust and reliable for filtering duplicates in financial texts.
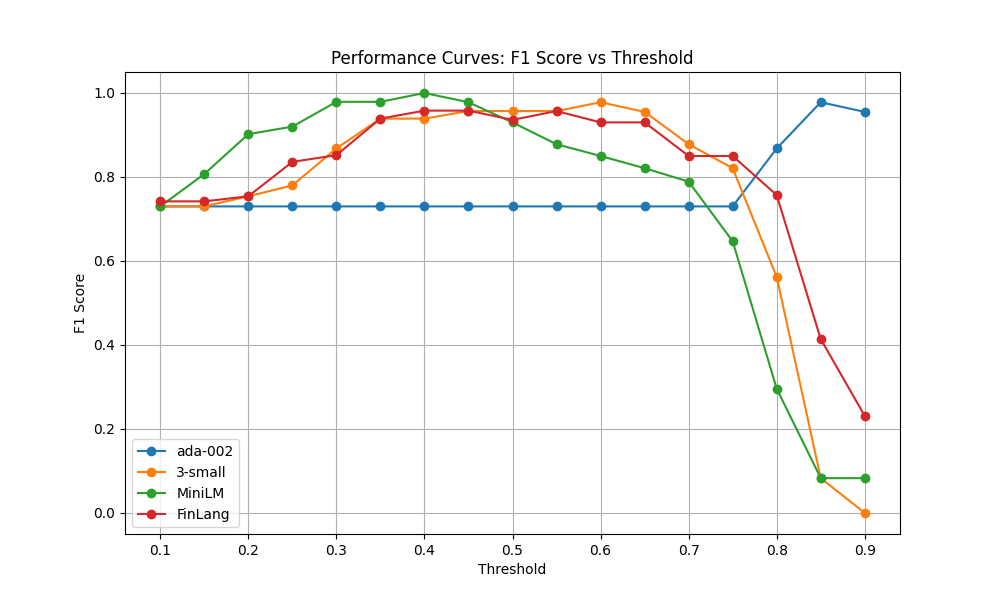 Image 3.5: I generated a graph using Matplotlib further illustrating the issue with MiniLM. This isn’t apparent when just looking at the data but in the graph it becomes clear that MiniLM’s performance rapidly declines when shifting the threshold. This is an issue because it shows that by proxy I’m risking a lot of misclassification when I start handling more diversed data. (Also the graph shows, in a very apparent way, how terrible ada-002 is for this use case).
Image 3.5: I generated a graph using Matplotlib further illustrating the issue with MiniLM. This isn’t apparent when just looking at the data but in the graph it becomes clear that MiniLM’s performance rapidly declines when shifting the threshold. This is an issue because it shows that by proxy I’m risking a lot of misclassification when I start handling more diversed data. (Also the graph shows, in a very apparent way, how terrible ada-002 is for this use case).
Conclusion
For the duplicate filtering workflow, I’m picking MiniLM over FinLang primarily because FinLang tends to undershoot—often misclassifying valid points as non-duplicates, which negatively affects precision. As a result of the hybrid approach I’ll outline in the next section it’s sensitive to prioritize catching all possible duplicates—even if it means initially flagging some false positives—over the risk of missing valid duplicate points. MiniLM’s ability to robustly flag potential duplicates makes it the preferred model for this application.